📤 Share
📝 Summary
Meta's text-guided multilingual universal speech generation model.
🏷 Tags
⭐ Rating
📖 Tutorials
📝 About This Tool
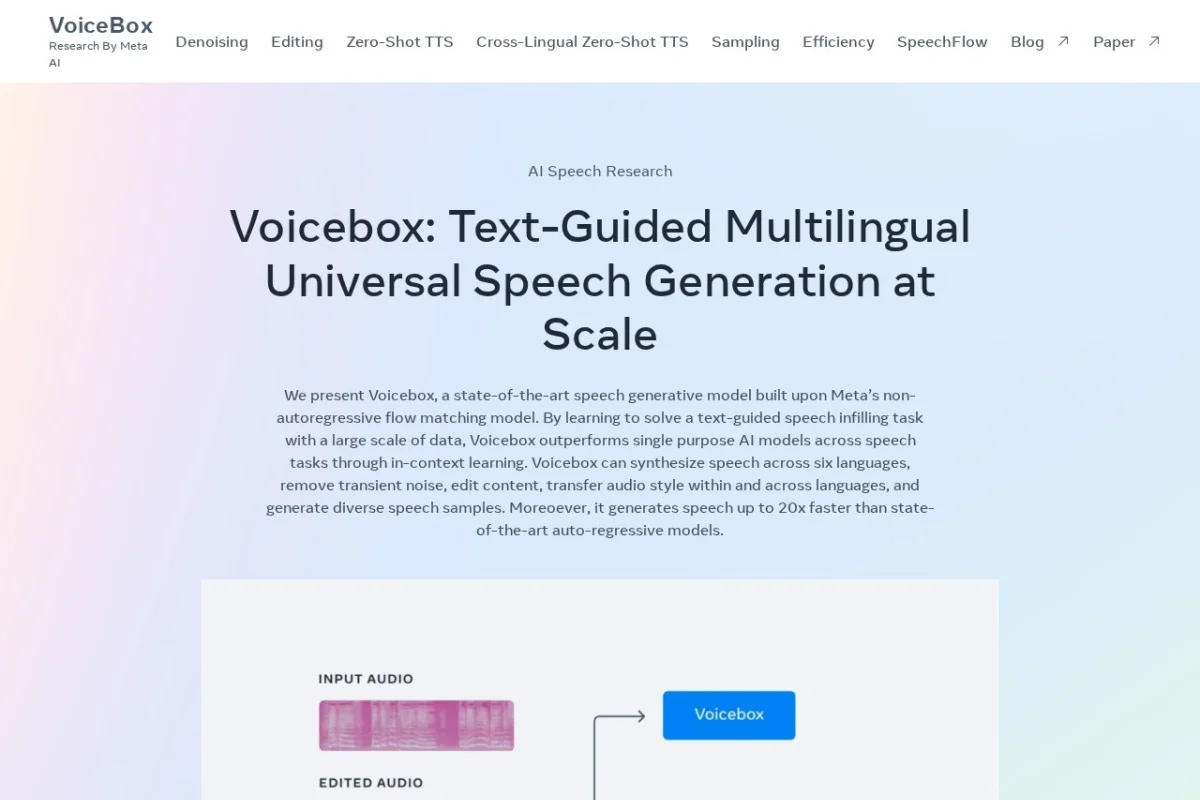
•VoiceBox is a state-of-the-art speech generative model by Meta AI based on non-autoregressive flow matching. It learns text-guided speech infilling at scale and can perform tasks like zero-shot TTS, cross-lingual style transfer, transient noise removal, content editing, and diverse sample generation across six languages. It generates speech up to 20x faster than autoregressive models through in-context learning.
⚡ Key Features
•Zero-shot text-to-speech synthesis
•Cross-lingual style transfer
•Transient noise removal
•Content editing
•Diverse speech sample generation
•Multilingual support (6 languages)
•20x faster than autoregressive models
✨ Why Choose It
•Non-autoregressive flow matching enables faster generation
•In-context learning without task-specific training
•Handles both past and future audio context
👥 Who Is It For
•AI researchers
•Speech technology developers
•Content creators
•Accessibility tool builders
❓ FAQ
Q: What languages does VoiceBox support?
A: English, French, German, Spanish, Polish, and Portuguese.
Q: Can VoiceBox remove background noise?
A: Yes, it can regenerate noise-corrupted speech to remove transient noises like doorbells or barking.
Q: Is VoiceBox open source?
A: The research paper and demos are available, but the model itself is not fully open source.